Sooo liebe Leute, hier ein kleines Projekt bezüglich des Plauschangriffes (und per se allen anderen RBTV Podcasts):
Da sich ja einige Leute beschwert haben, dass bei den neueren Plauschangriffen die Time Codes fehlen, dachte ich mir, es wäre vielleicht recht nützlich, wenn Puristen diese selbst hinzufügen könnten. Daher die Idee für ein kleines Programm, dass dem geneigten Podcast-Hörer erlaubt, die Meta-Daten der jeweiligen .mp3 Dateien zu manipulieren.
So weit so unspektakulär. Ziel meines kleinen Programmes soll es letztendlich sein, die Dateien aus Vorlage-Dateien automatisch formatieren zu können, sprich: Jemand (wahrscheinlich ich) macht sich die Mühe und schreibt die Time Codes heraus, erstellt eine Vorlage für die Plauschangriffe und der geneigte Plauschangriff-Hörer kann sich mit den Time Codes und neuen Formatierungen vergnügen…kurzum eben ein „erweiterter“ Plauschangriff oder eben Plauschangriff+ ^^
[details=Hintergrund]Wie wir alle wissen, stehen unsere Böhnchen unter ziemlichem Stress, weshalb es nicht verwunderlich ist, dass irgendwo Zeit eingespart werden muss. Leider haben die Einsparungen auch eins meiner liebsten Formate hier, den Plauschangriff getroffen. Waren zum Anfrang noch die Time Codes als lyrics eingespeichert und die Dateien vernünftig formatiert,
fehlten später leider Gottes die Time codes, was es etwas ungünstig machte, wenn man beim Plauschangriff einschlief (was während einer längeren Bahnfahrt schon einmal vorkommen soll
 )
)
Die Stallone Casts waren dann der technische Super-Gau, bei dem scheinbar die Formatierung komplett schief gegangen ist:
[/details]
Trivia
Ich weiß, dass das hier Meckern auf hohem Niveau ist, da der Plauschangriff immer noch prima ist, selbst ohne Time Codes. Schaue ich mir allerdings die anderen Podcasts/zum Podcast konvertierte Videos an, ähnelt ihre Formatierung doch arg dem der Stallone-Casts, kurzum: Sie ist nicht vorhanden. Daher kommen die anderen Podcasts an die Reihe, wenn ich mit dem Plauschangriff durch bin.
Aktueller Stand:
Inzwischen ist das Programm vollständig funktionionstüchtig. Es können sämtliche unterstützten ID3-Felder (~ 30) gesetzt werden. Desweiteren können Vorlagen gespeichert und wieder eingeladen werden. Außerdem ist es möglich selbige auch automatisch zu generieren (als Backup der Original Dateien) oder einzuladen (um die Tags automatisch zu setzen, sprich: Exakt die Funktion die ihr benötigt, wenn ich euch meine Metadaten-XML gebe).
Aktuelle Programmversion: 1.06.031 - 0009
Passwort: bohns
Getaggte Podcasts:
Plauschangriff: //
Almost Daily: 1 - 12
Wir müssen reden://
Animal Squad: //
Morriton Manor: //
Dysnomia: //
Nachspiel: //
Bohndesliga: //
Kino+: //
Bada Binge://
One on One://
Buchklub://
Press Select://
Beanstalk://
Erstellte Timecodes
[details=Almost daily]
[details=AD#1]> Der Startschuss für Almost Daily! In dieser Episode erklären Eddy, Nils, Simon und Fabian, was das Format „Almost Daily“ überhaupt ist, wie es zum Youtube-Kanal rocketbeanstv kam und sie fabulieren über die Wii U und das neue iPhone 5. Als Schmankerl erzählt Simon die Geschichte seiner beiden iPhones.
Inhaltsverzeichnis
00:00:00 - Intro & Begrüßung
00:00:20 - Was ist „Almost daily“ überhaupt?
00:03:08 - Simon promoted seine Internetpräsenz und Fabian fabuliert über seinen schrecklichen Twitternamen
00:05:31 - Die Regie spielt mit den Lichtern & Nils erklärt, wie er zu seinem Twitternamen kam
00:07:07 - Eddy erklärt wie es zu RBTV kam
00:08:27 - Nils führt „Almost daily“ als Podcast ad absurdum
00:12:29 - Simon und seine Gesprächskultur
00:13:45 - Der Unterschied zwischen Formaten auf gameone.de und RBTV
00:17:42 - Kurze Ausschweifung zu Tom Cruise
00:18:49 - Beginn des Themas Wii U
00:25:30 - Platinum Games und die Nerdrage über die Exklusivität von Bayonetta 2
00:29:40 - Warum spielen die Bohnen eigentlich nur auf XBox ?!?!?111
00:34:45 - iPhone 5: Heißer Schei* oder überteuerter Mist?
00:37:12 - Die Geburt des „Slappomobils“
00:38:20 - Schnitt zwischen den Teilen
00:38:48 - Das Problem von Apple
00:41:16 - Nils über das Design & Handling von Apple-Produkten
00:43:46 - Warum verkaufen sich Appleprodukte trotz ihres hohen Preises?
00:47:12 - Eddy schwärmt vom „MacBook Air“
00:50:43 - Der Vorteil des Apple-Universums
00:52:11 - Simon über iPhones & Waschmaschinen
00:54:22 - Wie Simon sein zweites iPhone verlor…
00:57:00 - Wie das Leben ohne Smartphone & Social Media war
00:58:10 - Verabschiedung & Ausblick auf weitere Episoden[/details]
[details=AD#2]> Was ist verkehrt mit Prometheus? Was gilt heutzutage alles als Spoiler? Und werden die Medien immer dümmer? Eddy, Nils, SImon und Daniel diskutieren, was es mit dem Fortsetzungswahn der heutigen Film- und Videospielindustrie auf sich hat und was es mit der Spoilerempfindlichkeit der heutigen Generation auf sich hat.
Inhaltsverzeichnis
00:00:07 - Begrüßung & Vorstellung der Gäste
00:02:11 - Simon raged über Daniels & Nils Mikro
00:04:06 - Nils über „Prometheus“
00:05:06 - Simon holt sich einen Kaffee, um nicht gespoilert zu werden
00:08:40 - Daniel wirft „Aliens“ als Vergleich in den Ring
00:12:42 - Was macht einen guten Film aus?
00:18:36 - Die Spoilerpussy Generation und der Schulhof
00:20:43 - Der Unterschied zwischen „verratenen Geheimnissen“ & Spoilern
00:25:35 - Was gilt als Spoiler?
00:26:29 - Schnitt zwischen den Teilen
00:27:38 - Nils und sein erstes Mal „Paranormal Activity“
00:30:06 - Eddy verteidigt das Nacherzählen von Filmen
00:31:05 - Detention, Cabin in the Woods, Crank & Scott Pilgrim
00:34:50 - Eddy und seine Liebe zu IMDb
00:37:24 - Werden Filme immer dümmer? Die Jungs diskutieren über Fortsetzungswahn, Markenorientierung & Parallelen zur Videospielindustrie
00:46:59 - Sind nur anspruchslose Werke erfolgreich? Wird Idiocracy zur Dokumentation? Fragen über Fragen
00:48:35 - Warum schauen Leute „Das Supertalent“ ?
00:49:47 - Set-top Boxen & Quotenverfälschung
00:51:40 - Schnitt zwischen den Teilen
00:55:07 - Werden die Leute dümmer oder suhlt man sich als Nerd nur zu sehr im eigenen Kosmos?
00:58:43 - Der Live-Charakter des Fernsehens & die Internetkultur
01:09:18 - Ist South Park das Leitbeispiel für Verfügbarkeit?
01:11:46 - Verabschiedung[/details]
AD#3
Webserien! Star Trek! Halo! Jenny Elvers! Und am Wichtigsten: Holodeck-Pornos! Dieser bunte Blumenstrauß an Themen wird von unserem Aufdeckungsreportern Eddy, Simon und Fabian knallhart investigiert.
Inhaltsverzeichnis:
00:00:07 - Begrüßung & Vorstellung des Themas
00:01:15 - Die Web/Fanserie Star Trek: Renegade & Star Trek im Allgemeinen
00:10:23 - Etiennes Einschlafhilfe: Star Trek: The Next Generation
00:14:18 - Warum fliegt man überhaupt durch das All, wenn man das Holodeck hat?
00:15:37 - Welche weltbewegenden Dinge wurden in Next Generation entdeckt, die das ganze Reisen rechtfertigen?
00:17:26 - Fragen über Fragen: Werden Holodeck-Prostituierte „weitergereicht“? Und was passiert mit ominösen Hinterlassenschaften des Vornutzers?
00:18:50 - Wird Alkohol wegen der Wirkung oder des Geschmacks getrunken?
00:20:02 - Kein Geld in Star Trek? Wie wurde dann der Bau der Enterprise bezahlt? Und wer will der Winker von hinten sein?
00:25:04 - Schnitt zwischen den Teilen
00:25:18 - Die Webserie Halo 4: Forward unto dawn
00:27:01 - Neil Bloomkamp: An neuer Stern am Nerdhimmel? Und warum ist es eigentlich so schwer, eine glaubwürdige Waffe für einen SciFi Film zu erfinden?
00:36:15 - Gibt es nur einen Master Chief?
00:38:32 - Das Problem des Extended-Universe
00:41:42 - Jenny Elvers betrunkener Auftritt in einer Talkshow - Eigenverschulden oder Fehler der Regie?
00:45:28 - Schnitt zwischen den Teilen
00:45:43 - Unangenehme Gäste bei GIGA
00:47:33 - Muss man Leute vor sich selbst schützen?
00:58:37 - GIGA und der Anschlag vom 11. September
01:01:43 - Gottschalk und sein Ausstieg aus Wetten dass…?
01:04:05 - Verabschiedung & Ausblick auf kommende Episoden[/details]
[details=AD#4]> Die Meldung des Jahres: George Lucas verkauft sämtliche Rechte an Star Wars an Disney. Welche Auswirkungen hat das auf die Zukunft des Franchises? Und wie wird die neu angekündigte Trilogie aussehen? Eddy, Simon, Nils und Gregor spekulieren über die Zukunft einer weit entfernten Galaxie.
00:00:05 - Begrüßung & Vorstellung des Themas: George Lucas verkauft alle Rechte an Star Wars an Disney
00:04:52 - Star Wars & Merchandise oder: Warum die Prequels schlecht waren
00:08:47 - George Lucas Motivation für die Prequels: Geld verdienen oder künstlerische Vision?
00:12:07 - Angriff der Klonkrieger: Besser als Die dunkle Bedrohung oder auf gleichem (niedrigen) Niveau?
00:14:21 - George Lucas neue Rolle für Star Wars
00:16:36 - Böse Worte zu Carry Fisher
00:19:30 - Wer wird der Regisseur für den neuen Star Wars?
00:24:26 - Wieviel Extended Universe wird im neuen Film stecken?
00:25:22 - Schnitt zwischen den Teilen
00:25:29 - Welcher Regisseur den Jungs am liebsten wäre
00:32:53 - Simon und „Die nackte Bedrohung“
00:45:25 - Ohne Palpatine und Vader: Wer wird der Bösewicht in der neuen Trilogie? Wird die Galaxie von Haselpfarf vom Planeten XY3 bedroht?
00:49:50 - Schnitt zwischen den Teilen
00:49:57 - Jedigeister & Logik
00:53:30 - Han Vader, Darth Chewbacca oder doch eher Count D2?
00:58:03 - Die „Admiral Thrawn“ - Reihe: Ideengeber für die neue Trilogie?
01:01:10 - Die unglaubwürdige Wandlung des Anakin S.
01:07:31 - Verabschiedung[/details]
[details=AD#5]> Hat man als Person der Öffentlichkeit automatisch eine Vorbildfunktion? Sind Leute, die sich an einem Shitstorm beteiligen eigentlich nur neidisch und Hater? In dieser Episode debattieren Eddy, Budi, Nils und Simon über das Internetphänomen „Shitstorm“ und seine Auswirkung auf die Karriere Medienschaffender. Zuvor reden sie allerdings ausführlich über die „Mondlandung“ dieser Generation: Felix Baumgartners Fallschirmsprung aus der Stratosphäre!
00:00:05 - Begrüßung
00:01:18 - Felix Baumgartners Fallschirmsprung aus der Stratosphäre
00:07:36 - Der Fallschirmsprung von Simon & Budi in der ersten Game One Folge
00:12:13 - Sind die Kosten für Baumgartners Sprung moralisch vertretbar?
00:20:03 - Braucht jede Generation ihre „Mondlandung“?
00:22:56 - Der Grund für die Abschaltung von Baumgartners Helmkamera
00:29:04 - Baumgartners Mentor Joseph Kittinger & sein Sprung aus 32 km Höhe
00:30:36 - Schnitt zwischen den Teilen
00:32:43 - Der Shitstorm rund um Joko & Klaas
00:41:39 - Sind Leute, die sich an Shitstorms beteiligen, bloß neidisch? Wird einfach sinnlos „gehatet“, statt Geschehnisse unvoreingenommen zu reflektieren?
00:44:19 - Eddy zu Gast bei „Rent a Pocher“
00:52:29 - Haben Joko & Klaas eine Vorbildfunktion? Haben sie ihren „Streich“ durch die Ausstrahlung verharmlost?
00:55:28 - Verabschiedung[/details]
[details=AD#6]> Alles rund um die abgedrehte Zeichentrickkunst der Japaner, oder kurzum: Animes! In dieser Episode reden Budi, Ian, Tim und Schröck über ihre Kindheitserfahrungen und ihren ersten Kontakt mit Animes und reißen als erste große Serie One Piece an, bevor sie die Eieruhr gnadenlos absägt und auf den nächsten Teil vertröstet.
00:00:05 - Begrüßung und Vorstellung des Themas Anime
00:02:52 - Tim berichtet von seinen Kindheitserfahrungen und dem ersten Kontakt mit dem Medium „Anime“
00:06:02 - Budi & die Glotzposition
00:09:05 - Schröck über die unterschiedlichen Erzählstrukturen von asiatischen und westlichen Medien
00:11:36 - Entlädt sich die asiatische Höflichkeit in Animes? Sind die gezeigten Extrema die Folge eines restriktiven Lebens? Oder sind Japaner einfach lockerer bezüglich Sex & Gewalt?
00:18:11 - Was ist der erste Anime, an den sich die Jungs erinnern?
00:21:54 - Was hat den Hype um Animes ausgelöst?
00:23:50 - Schnitt zwischen den Teilen
00:23:59 - Ein kurzer Ausflug zum Pokémon Anime
00:26:16 - Budis Verhältnis zu Samurai Champloo & Cowboy Bebop
00:29:59 - Der erste große Brocken: One Piece & seine 500+ Folgen
00:32:28 - Was hält den geneigten Zuschauer bei One Piece bei der Stange?
00:35:22 - Schröcks Kritik an One Piece: Ist nicht klar, wer der Hauptprotagonist ist?
00:36:32 - Was haben die Jungs aus bestimmten Animes gezogen? Was fanden sie gut?
00:39:50 - Das Beste zum Schluss? Hunter x Hunter
00:42:13 - Ausblick fürs nächste Anime Almost Daily: Sword Art Online
00:45:20 - Verabschiedung[/details]
AD#7
Nintendos neue Konsole ist in die Redaktion gepurzelt und Eddy, Nils und Fabian konnten es sich nicht nehmen lassen, sie ausführlich zu untersuchen und über die ersten Titel zu palavern
00:00:14 - Begrüßung & Vorstellung des Stargasts Wii U
00:01:22 - Fabian erklärt den Unterschied zwischen dem Basis und dem Premium Pack
00:02:48 - Der große Augenblick: Die Wii U verlässt ihre Packung
00:08:02 - Das Wii U Tablet: Überraschend okay
00:12:37 - Löblich: Nintendo spendiert ein HDMI-Kabel
00:14:53 - Weniger löblich: das fette Stromteil
00:15:47 - Eine kurze Pause zum Anzocken von „New Super Mario Bros. U“ und „Nintendo Land“
00:17:01 - Der erste Eindruck vom neuen Mario
00:22:26 - Nintendo Land: Einfallslose Minispielsammlung oder leckerer Happen für die Wartezeit auf Mario Party?
00:29:25 - Hiobsbotschaft für Eddy: Seine Vespa wurde hinterrücks ermordet
00:29:46 - Schnitt zwischen den Teilen
00:30:02 - Entwarnung: Eddy hat vergessen, dass er seine Vespa daheim gelassen hat
00:32:32 - Hacks & Tweeks für die Wii U
00:34:20 - Fazit zu „Nintendo Land“
00:34:54 - ZombiU: Der erste Core-Titel für die WiiU
00:37:22 - Das Problem von Multiplattform-Titeln: Der gimmickhafte Einsatz des Tablets
00:43:01 - Wieviel Grafikpower steckt in der Wii U?
00:47:11 - Verabschiedung
Anleitungen
Wie kann ich meine MP3s taggen?
Folgt noch
Wie kann ich eigene Vorlagen erstellent & verwenden?
Folgt noch
Entwicklungsgeschichte
Edit #1:
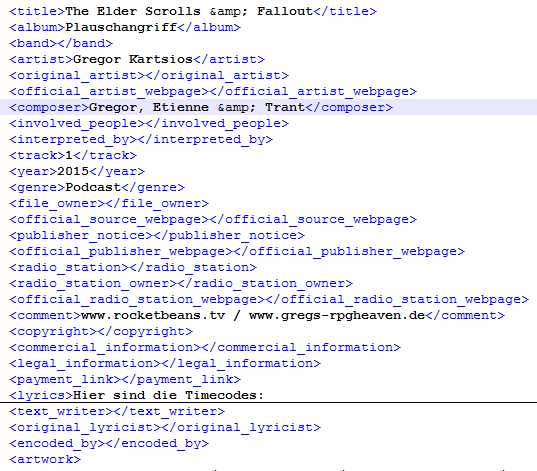
Schreiben der Meta-Daten klappt inzwischen auch. Hier mal als Beispiel eine modifizierte Version des ersten Teils von „Animal Squad“, welche im Original keinerlei Daten außer der Jahreszahl enthält:


Edit #2: Speichern der Templates als .xml klappt jetzt auch:
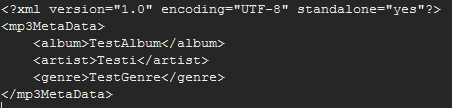
(war zu faul, alle Daten einzugeben, also sind derzeit nur das Album, der Künstler und das Genre drin ^^)
Edit #2 extended:
Hier mal die Meta-Daten des Bethesda PAs als .xml:
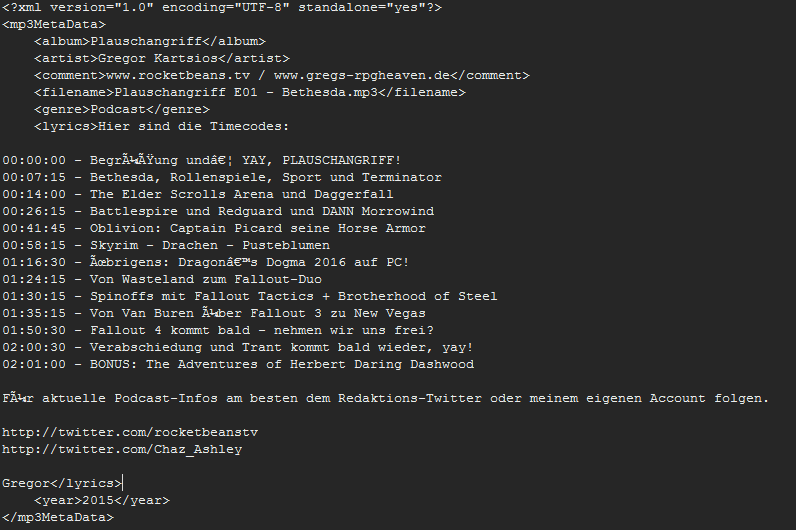
Das einzig komische sind Kodierungsfehler der Lyrics

Edit #3: Okay, die Kodierungsfehler dürften an der UTF-8 Kodierung liegen, dass gleiche Problem hatte ich bei RocketBase auch ^^ Umstellen auf ISO-8859-1 dürfte da Abhilfe schaffen
15.04.17
Zwischenupdate:
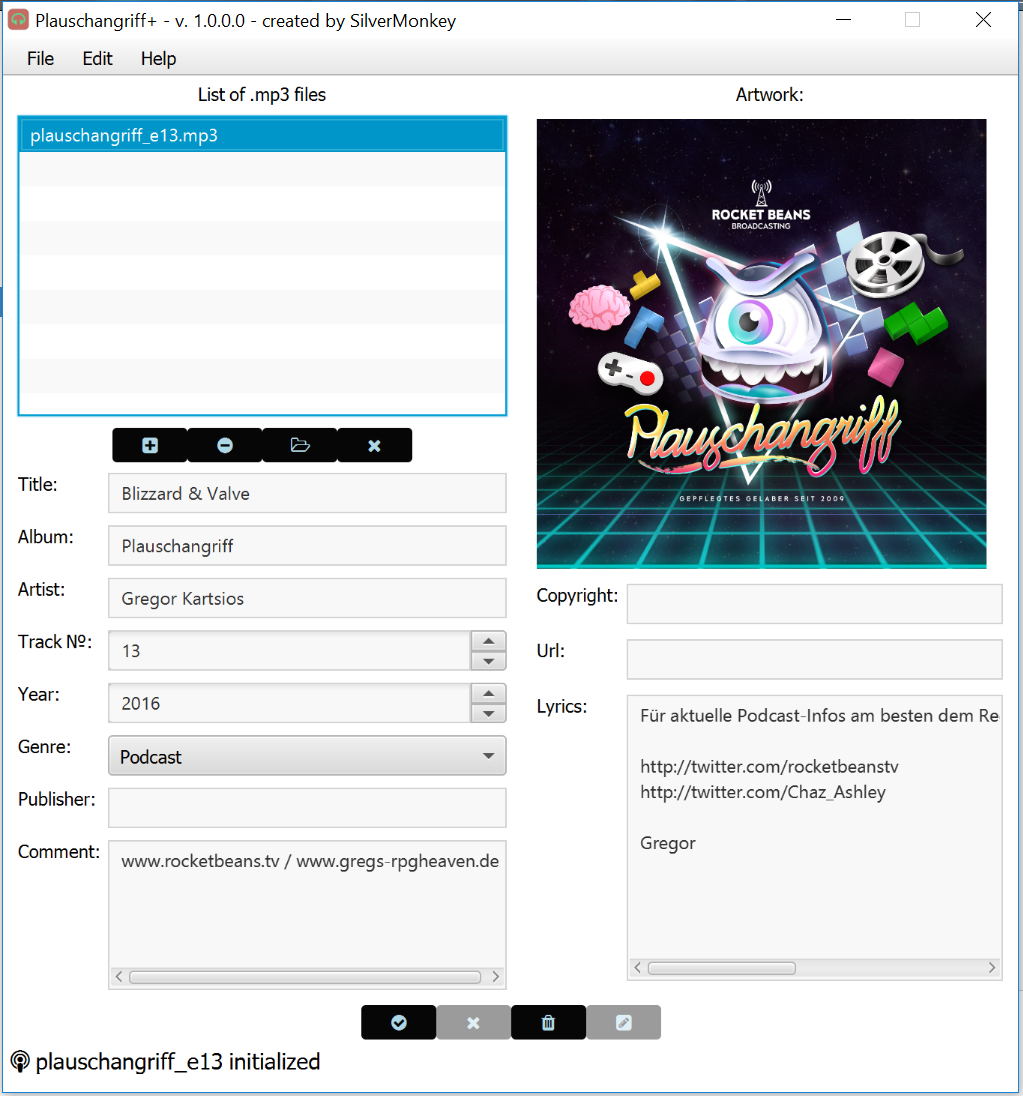
Diesmal habe ich hauptsächlich am GUI des Programms gearbeitet. Die Änderungen umfassen als erstes augenscheinlich eine Umsortierung der jeweiligen Felder, um das Ganze etwas sinniger aufzubauen. Außerdem habe ich die zwei Textfelder für das Jahr und die Tracknummer durch den sinnigeren Spinner ersetzt, der nur (Ganz)Zahlen akzeptiert. Am Wichtigsten bezüglich der Änderungen dürfte das Einbauen einer ChoiceBox für die jeweiligen Genres sein, da ich kaum glaube, dass sich irgendjemand die ~180 ID3v1 Genres merken kann ^^
Desweiteren habe ich am unteren Ende eine kleine Statusleiste eingefügt, die über die jeweils zuletzt durchgeführte Aktion informiert sowie alle Bestandteile mit Tooltips ausgestattet.
Als kleines Schmankerl kann man sich jetzt bei Bedarf auch per Rechtklick das jeweilige Albumartwork als PNG abspeichern ^^
Rein optisch habe ich das Programm soweit an meinen [TEARS/BEARDS Karteneditor] (Tears/Beards Karten-Editor) angepasst ^^
Intern habe ich meine Metadaten-Klasse etwas umgebaut und hoffe erstmal, dass das es dadurch möglich wird, die Templates auch wieder zu laden. Aber mal schauen ^^
Edit:
Okay, ich habe den Fehler gefunden…scheinbar ist JXBA zu blöd, deutsche Umlaute richtig in ein XML-file zu schreiben…was dazu führt, dass er sie danach auch nicht mehr laden kann…darauf muss man erstmal kommen ^^
Muss erstmal schauen, wie ich das Problem umgehe, dürfte allerdings nicht all zu schwer sein. Muss es vor dem abspeichern einfach durch Unicode chars ersetzten.
Edit 2:
Speichern und laden klappt jetzt, jetzt muss ich die Templates nur noch anwenden und das übernehmen von spezifischen Templates automatisieren, dann kann ich damit anfangen, für die RBTV Plauschangriffe die jeweiligen Timecodes herauszuschreiben ^^
Edit 3: Habe auch endlich den Fehler gefunden, den die Bibliothek geschmissen hat, wenn man versucht hat, die Tags in die gleiche Datei zu schreiben und nicht die veränderte .mp3 als neue Datei zu speichern. Der Übeltäter war die Angabe StandardOpenOptions.TRUNCATE_EXISTING, was dafür sorgt, dass der geöffnete ByteStream die Datei, insofern sie existiert, auf 0 bytes eindampft und dann weitermacht. Keine Ahnung warum das da so angegeben wurde, hat mich eine ganze Weile gekostet, das überhaupt herauszufinden.
Edit 4: Okay, das Überschreiben hat so zwar halbwegs geklappt, aber es wurden, warum auch immer, nicht mehr alle Tags richtig gesetzt. Habe beschlossen, wieder die Original-Version der Bibo zu verwenden und einen Bypass als zweiten Plan zu legen, sprich: Speichern der geänderten Datei als Zweitdatei, löschen der Originaldatei und Umbenennen der Zweitdatei. Ist zwar etwas unelegant, aber da die Bibliothek keinerlei Quellcode-Kommentare/Docs hat, ist es derzeit wohl die einfachste Lösung ^^
Edit 5: Okay, das klappt doch besser als gedacht, also kann ich mich jetzt daran machen, die Templates vernünftig zu implementieren
Edit 6: Sooo, mal wieder ein kleines Update. Die Templates funktionieren soweit, also beginnt jetzt der mühselige Part, bei dem ich anfangen muss, die jeweiligen Timecodes für die Plauschangriffe zu erstellen.
Außerdem hat sich noch ein klein wenig was am Interface getan und ein paar neue Funktionen sind hinzugekommen:
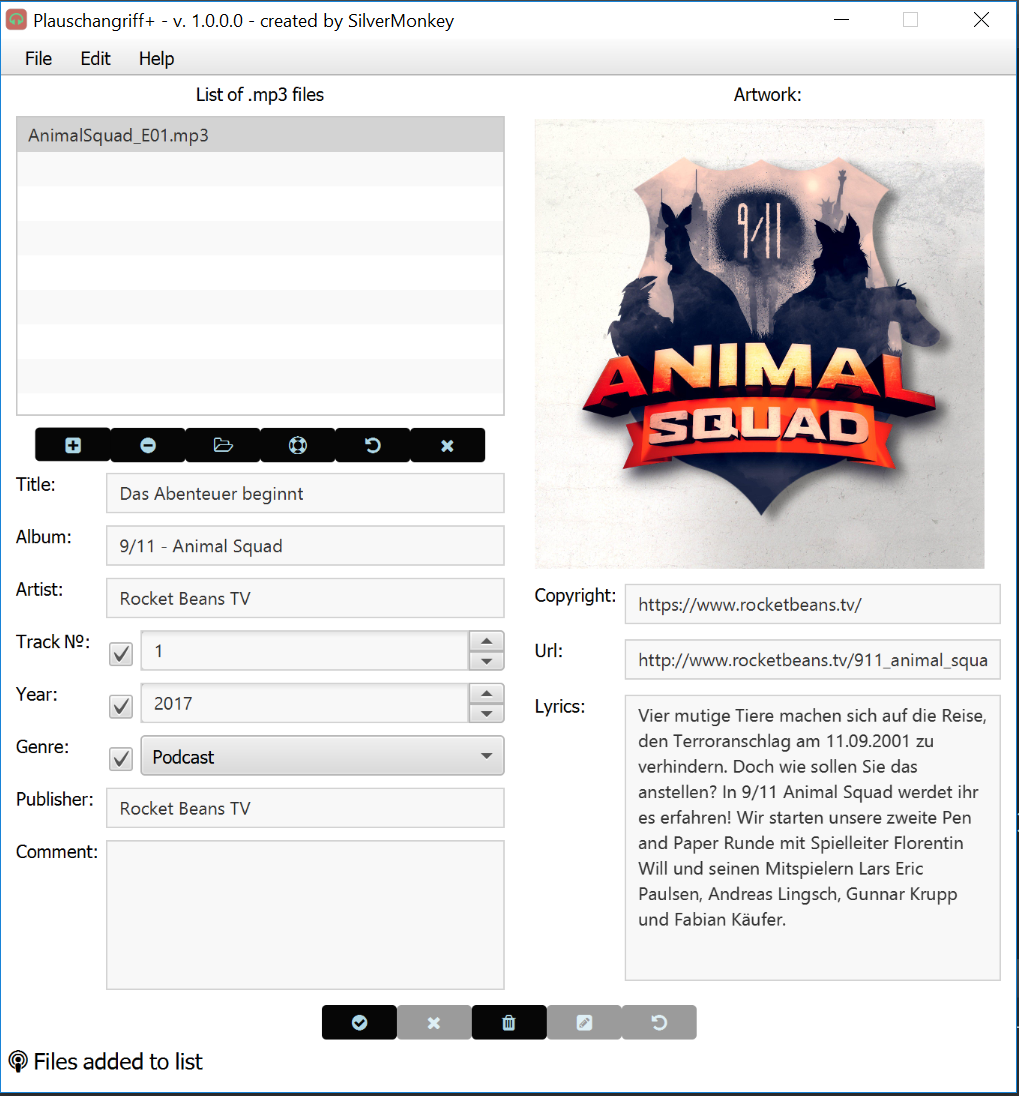
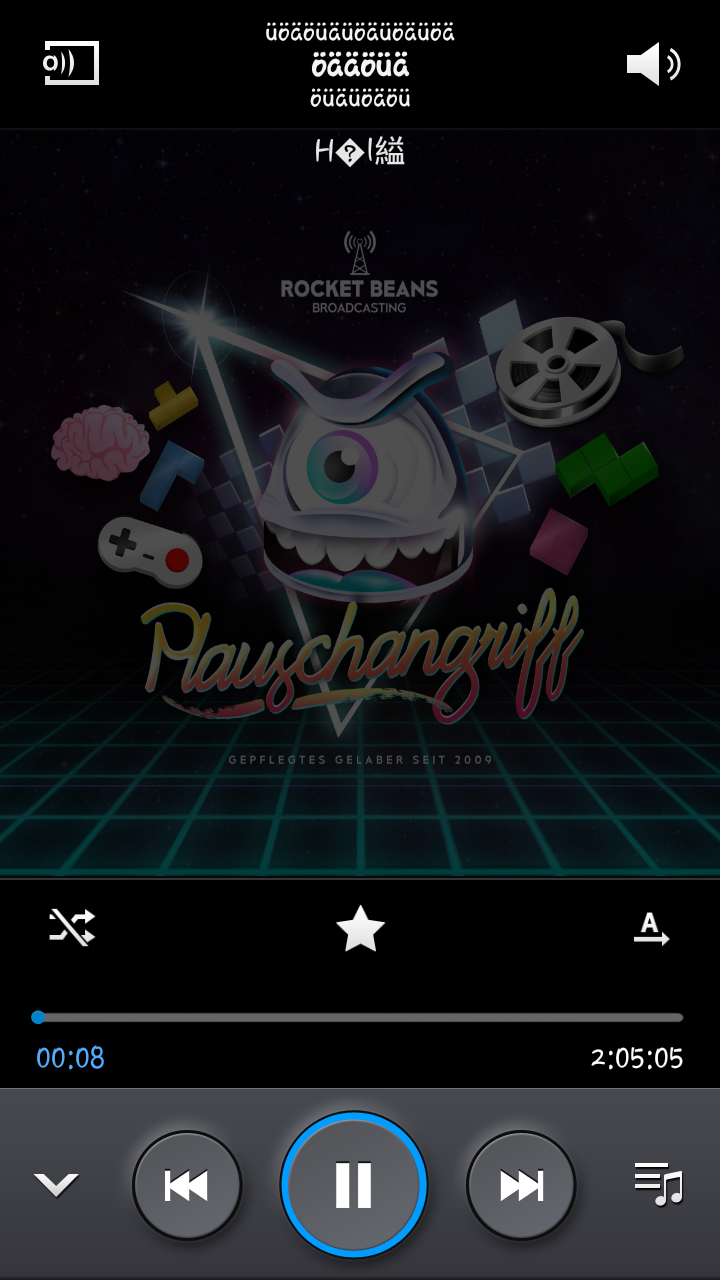
So würde die oben im Programm geladene Datei dann übrigens auf dem Handy aussehen:
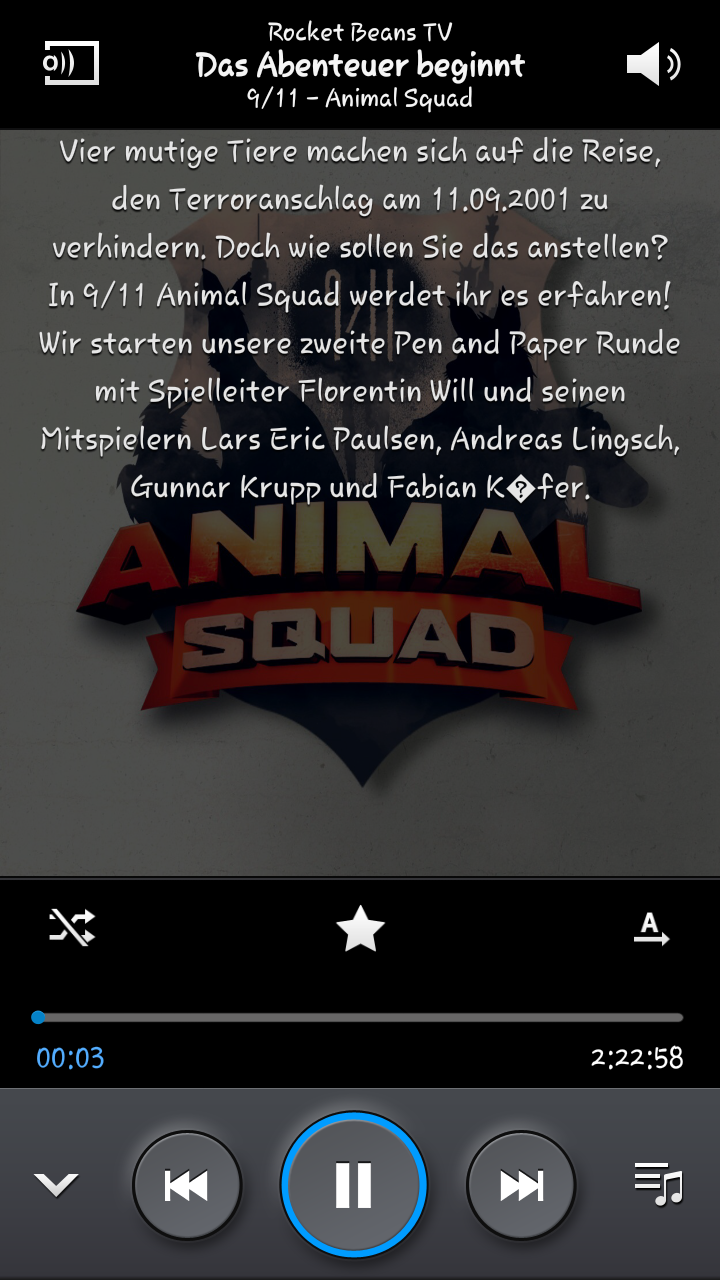
Ich weiß allerdings mal wieder nicht, was das Problem mit den Umlauten ist, vernünftig als UTF-8 gespeichert wurde alles.
Update 24.04.17:
Update!
Dank vier kleiner Zeilen

dürften die internen Encoding-Probleme, mit denen ich mich die letzten Tage herumschlagen durfte, endlich der Vergangenheit angehören.
Zum Hintergrund der Probleme sei gesagt, dass ich versucht habe dem Nutzer die Möglichkeit zu geben, die Originalen Metadateien abzuspeichern um sie bei Bedarf wiederherstellen zu können (falls einem die Änderungen dann doch nicht gefallen). Problem dabei war, dass es mir zwar möglich war, die Daten zu speichern, jedoch nicht, sie wieder einzuladen…was äußerst seltsam war, da die Bibliothek, die sie einlesen sollte, sie auch geschrieben hat, mir jedoch vorwarf, dass der Header der .xml Dateien nicht gültig war. Das Problem trat scheinbar auf, da ich dem „Unmarshaller“ nicht explizit mitgegeben habe, dass die Datein UTF-8 encodiert sind…was eigentlich auch gar nicht nötig sein sollte, da UTF-8 als Standard Encodierung angenommen wird (oder besser: werden sollte). Lange Rede, kurzer Sinn: Durch Einsatz obriger 4 Zeilen hat sich das Problem dann auch erledigt.
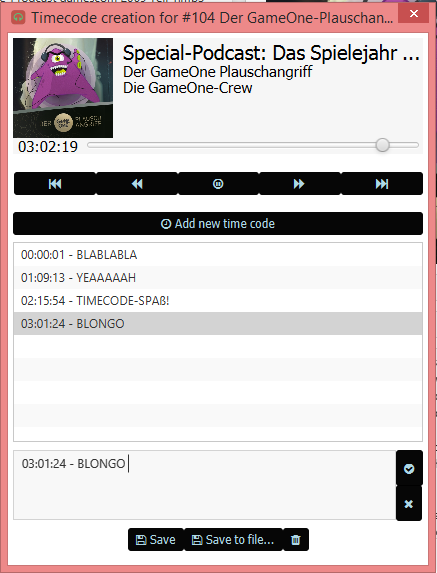
Weitere gute Nachrichten gibt es bezüglich der Erstellung von Timecodes:
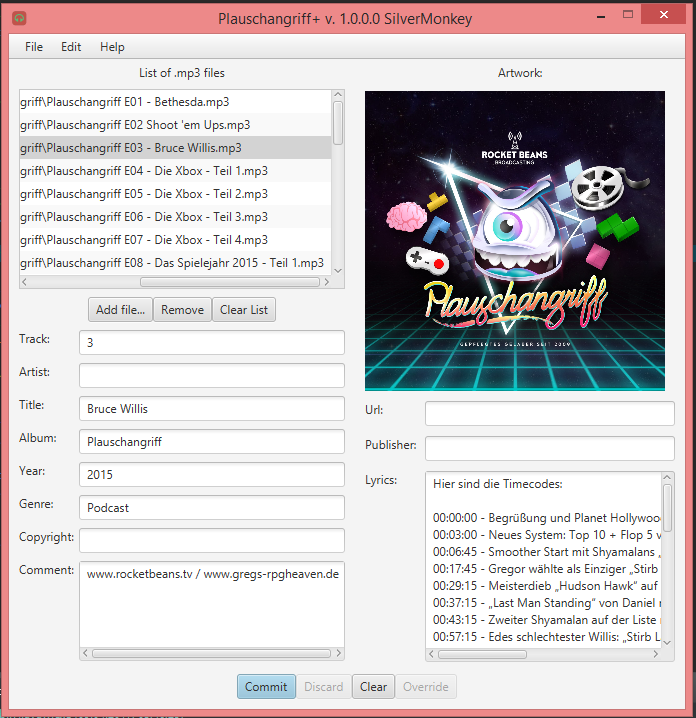
Für diese Aufgabe habe ich mir inzwischen ein kleines komfortables GUI gebastelt, welches diese Aufgabe vorzüglich unterstützt
Edit:
Hier schon mal die originalen Metadaten der alten G1 Plauschangriffe:
Klick
Passwort: bohns
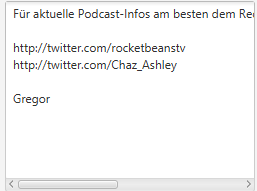
Edit2: Die Lyrics haben (zumindest auf meinem Handy) immer noch ein Problem mit Umlauten. Nach einer kurzen Untersuchung könnte das Problem an Folgendem liegen:
//Liste mit Encodings der jeweiligen Plauschangriffe, welche hauptsächlich in ISO kodiert waren
Könnte eventuell nicht ganz hinhauen, da unkodierte UTF-8 Strings reinzuhauen. Weiß allerdings auch nicht, ob es hilft, sie vorher zu enkodieren, muss ich ausprobieren. Finde es auch kurios, dass die Lyrics mal so mal so kodiert sind, während der Rest meistens ISO ist.
Update 29.04.17:
Edit: Gerade einen weiteren Editor für Tags ausprobiert, den „Kid 3 Tag Editor“. Gleiche Tags eingefügt, werden anstandslos angezeigt.
Edit2: Da ich gerade leicht genervt bin, lasse ich mp3agic kurz fallen und schaue mir mal an, was beaglebuddy als Bibliothek so draufhat. Drückt mir die Daumen, dass die Bib hinhaut…ist auch noch gar nicht so alt, wurde 2015 das letzte Mal aktualisiert.
Edit3: Ich fasse es nicht, BeagleBuddy hat tatsächlich das Wunder vollbracht:
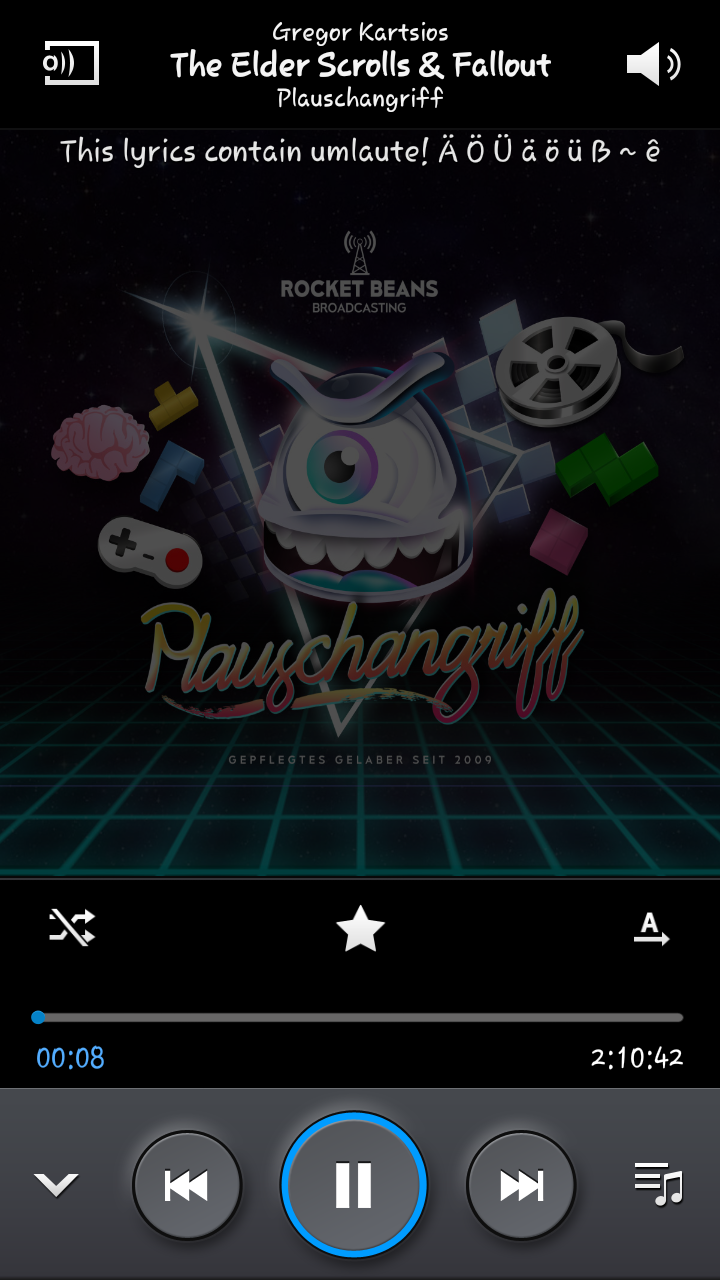
Jetzt müde, morgen mehr
Update 30.04.17:
Programm wurde jetzt erfolgreich auf die neue Bibliothek aufgesetzt und funktioniert soweit wieder.
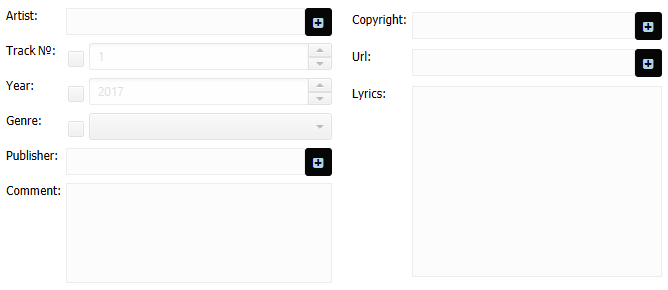
Ich konnte es mir allerdings nicht nehmen lassen, schon eine kleine Erweiterung zu planen, die es ermöglichen soll, so gut wie alle ID3 Tags zu setzen:
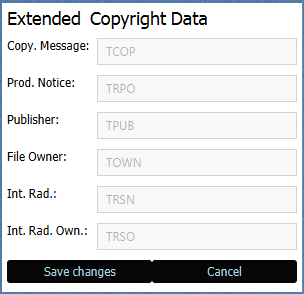

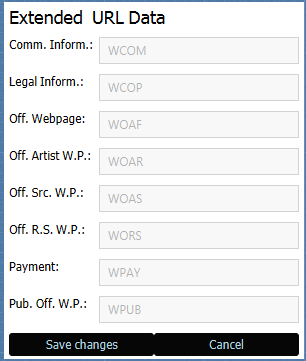
Aufgerufen werden die Interfaces dafür dann von kleinen Buttons neben den entsprechenden Feldern:
Edit: Die zusätzlichen Tag Interfaces funktionieren inzwischen. Jetzt muss ich nur die Metadaten-XMLs anpassen und ein paar kleiner und mittelgroße Änderungen/Erweiterungen vornehmen, dann kann ich euch die erste Testversion des Programms zur Verfügung stellen und danach anfangen, die jeweiligen Timecodes zu erstellen 
Edit2:
Sooo, dass Programm wurde soweit umgebaut, Metadaten-XMLs können auch wieder vernünftig gespeichert werden.
Hier eine Liste der inzwischen unterstützten Felder:
11.05.17
Update!
Hier eine erste Testversion zum Ausprobieren (für alle die das Programm mal testen möchten). Ist noch nicht ganz perfekt, funktioniert aber in sämtlichen Hauptpunkten.
Passwort: bohns
Edit: Gerade noch einen kleinen Fehler behoben, der manchmal verhinderte, dass ein Album-Artwork angezeigt wurde (lag daran, dass immer versucht wurde, dass Front-Cover zu laden,was Gregor teilweise aber nicht gesetzt hatte)
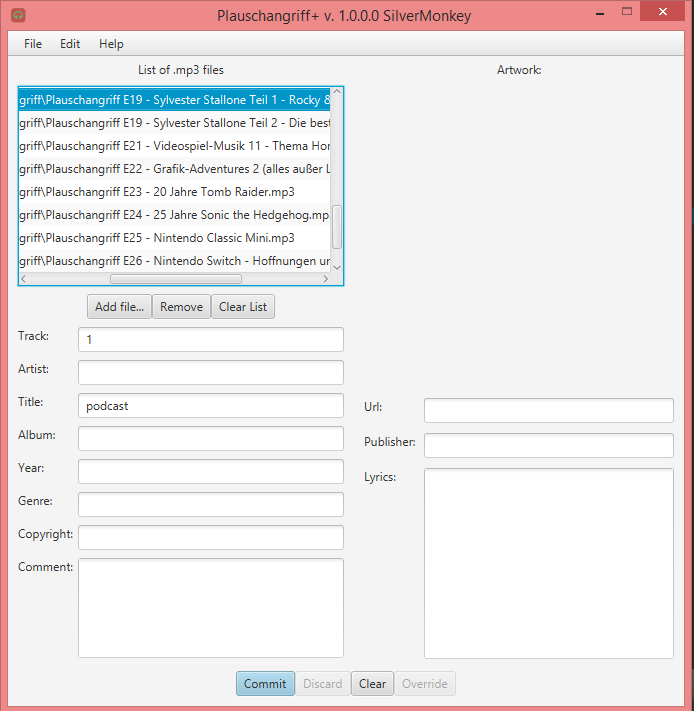
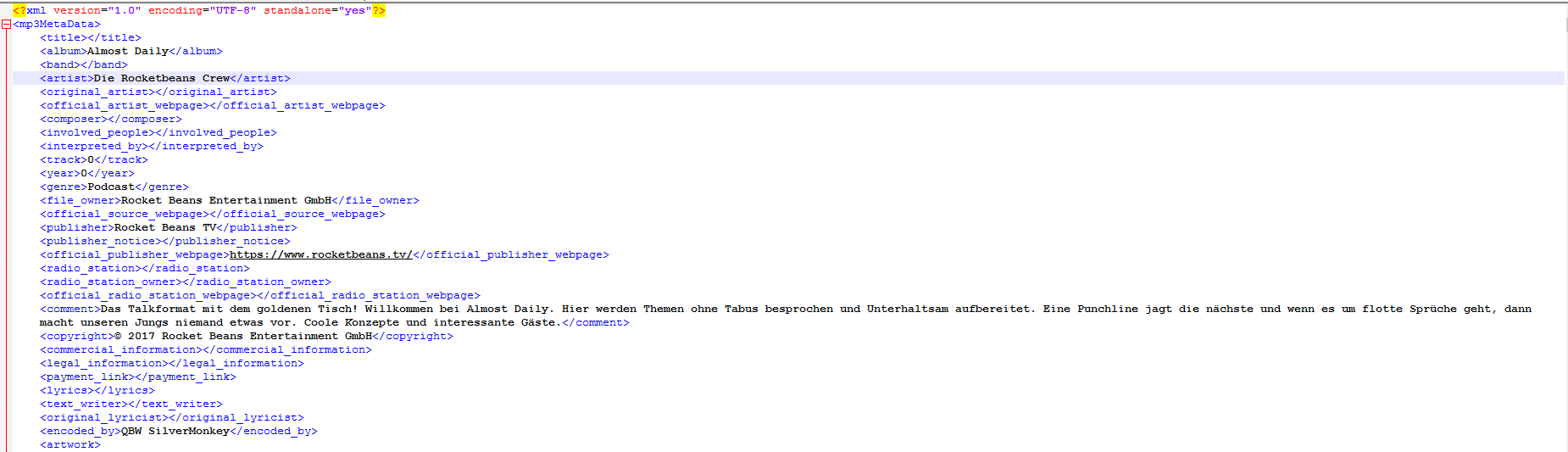
Edit2: Sooo, ich habe mir mal den Spaß gemacht, die ersten 20 Almost Dailys richtig zu taggen:
Das verwendete „General template“:
Die Dateien im normalen Windows Explorer
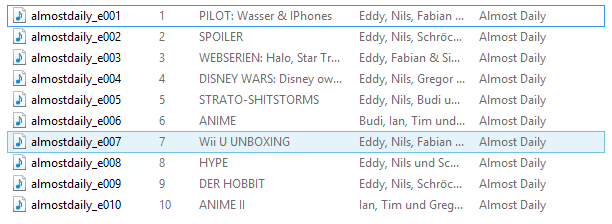

Die Dateien im PPlus
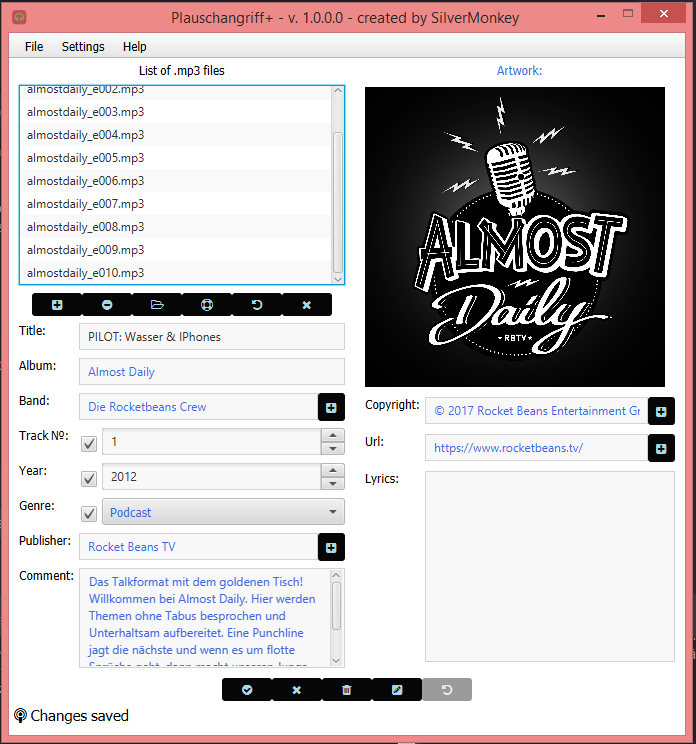
Dabei sind mir bis jetzt noch 14 kleinere Bugs aufgefallen:
Verwendet man ein „General Template“ wird keine Farbänderung in den „Extended“ Fenstern anzeigt, welche Felder genau vom template geladen werdenWenn die Kategorie „Genre“ durch das Template gesetzt wird, wird sie nicht selektiert (d.h. sie wird auch nicht gespeichert, wenn man nicht die CheckBox anklickt)Ändert man Felder in den ExtendedFrames und speichert diese, wird diese Änderung beim erneuten Öffnen nicht angezeigt, bis die Metadaten per „Commit changes“ gespeichert werden.Das Feld „File owner“ im Fenster „Extended Copyright Data“ wird nicht richtig gesetzt, wenn ein „General template“ geladen wurde- Das Feld „Band“ wird im „General Template“ im Feld „Artist“ gespeichert, welches eigentlich für das Feld „Lead Performer“ vorgesehen ist.
Nach dem Laden eines „General Template“ wird der Listener für Metadaten-Änderungen auf „true“ gesetztÄnderungen in den „Extended“ Fenstern führen nicht dazu, dass der Listener für Metadaten-Änderungen auf „true“ gesetzt wirdEs wird nicht angezeigt, wenn ein neues File geladen wird (normalweise wird der Status gesetzt)Scheinbar werden das Feld „Official Webpage“ und „Publisher Official Webpage“ nicht vernünftig gesetzt/gespeichertScheinbar wird das „Encoded by“ Feld nicht richtig gesetzt, wenn es von einem „General Template“ geladen wirdBeim Laden mehrerer Dateien nacheinander wird der Zwischenspeicher für die „Extended“ Fenster nicht geleert. Das führt dazu, das darin gesetzte Felder auch in weitere Dateien geschrieben werden, ohne das dies beabsichtigt war.Die Dateiliste wird nicht nach dem Dateititle sortiert, sondern neue Dateien werden einfach ans Ende gehängtDer Button „Save to file“ im Fenster „Timecode Creation“ macht bisher noch nichts- Das Feld „Involved People List“ führt bisher noch zu einer Exception, sollte man versuchen es zu setzen
Edit3:
Ich habe mir jetzt mal die Mühe gemacht und die Timecodes für das erste AD erstellt, um auszutesten, wie gut mein Programm sich dafür eignet. Bisheriges Fazit: Das Programm an sich funktioniert dafür ziemlich gut, ich würde allerdings noch ein paar interne Stellschrauben verändern, die das Ganze etwas verbessern.
Da das jetzt die erste Testblase war, möchte ich euch fragen, was ihr von den erstellten Lyrics haltet:
//Link zu den Almost Daily Timecodes
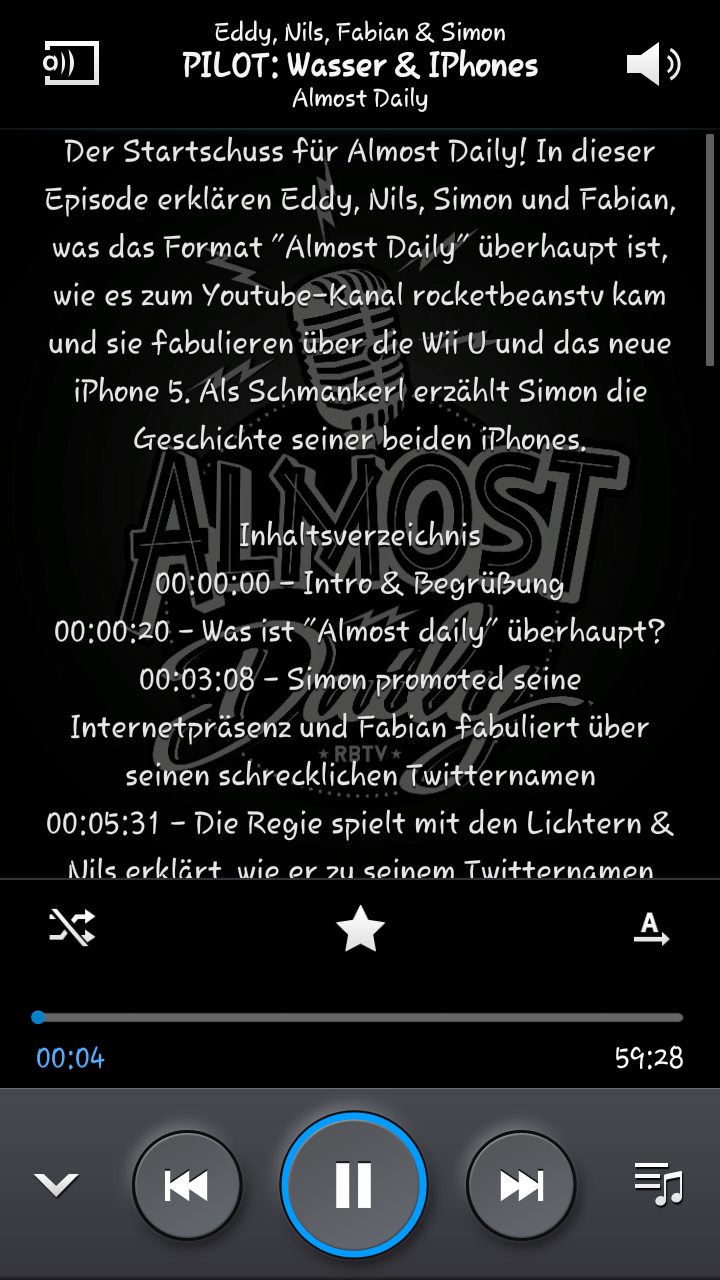
Ich persönlich bin noch nicht gänzlich zufrieden, finde sie aber soweit passabel.
Was haltet ihr davon?
Anmerkung: Ich muss „Lead Performer“ und Band beim Taggen austauschen
Anmerkung #2: Nicht wundern, dass die Timecodes von Episode zu Episode weniger werden, die Jungs werden einfach strukturierter, was mir ermöglicht, nicht immer alle 2 Minuten auf die Timecodes-Taste hämmern zu müssen ^^
Zum weiteren Ablaufplan: Ich werde jetzt erstmal die ersten 20 Episoden von Almost Daily vernünftig taggen und mit Timecodes ausstatten. Sobald ich damit fertig bin, haue ich eine neue (hoffentlich bugfreiere) Version meines Programms raus, zusammen mit den jeweiligen Templates für die Dateien. Daneben werde ich dann noch eine Anleitung hochladen, wie man mit meinem Programm die Templates dann auch ohne viel Aufwand einsetzen kann, da ich denke, dass sich das nicht zwingend aus dem Programm selbst erschließt, da es inzwischen ja doch etwas komplexer geworden ist ^^
Habe inzwischen eine neue Version des Programms unter dem gleichen Link hochgeladen.
20.05.17
Sooo, ich habe hier im Fred mal etwas, der Übersicht halber, aufgeräumt. Der Startpost wurde aktualisiert und enthält nun alle relevanten Informaten sowie einen Link zum Programm und eine Auflistung der Podcasts und der jeweils getaggten Episoden. Desweiteren werden die jeweiligen Timecodes gelistet, und sobald das erste 20. Paket fertig geschnürt ist, lade ich die Metadaten hoch und stellte dort dann auch den zugehörigen Link rein.
In nächster Zeit werde ich dann noch eine kleine Anleitung zusammenschustern, wie man die von mir bereitgestellten Metadaten möglichst einfach über seine MP3s ziehen kann
Notiz an mich: Laden & Speichern der Artworks überarbeiten.
Sonstiges:
Aktueller Stand bis 20.05.17
Dank einer wunderbar funktionierenden Bibliothek funktioniert das Auslesen der jeweiligen Meta-Daten tadellos (wie ihr auch an den Bildern sehen könnt). Das Schreiben wird dank Selbiger aller Wahrscheinlichkeit nach ebenso kein Problem sein. Was derzeit noch offen ist, ist die Erstellung der jeweiligen Templates. Dafür werde ich wahrscheinlich .xml Dateien verwenden, aber ich muss mal schauen, dürfte kein zeitaufwendiges Problem sein.
Was mehr Zeit in Anspruch nehmen wird, ist das Herausschreiben der Time codes, was aber bei der überschaubaren Menge an RBTV Plauschangriffen und der relativ langsamen Neuerscheinungsrate machbar sein dürfte.
Ansonsten fehlt halt noch Feinschliff am Programm ^^