Soooo liebe Leute, da ich mich gerade mit relationalen Datenbanken beschäftige, ist mir in den Sinn gekommen, wie nützlich es doch wäre, eine funktionelle SQlite Datenbank mit wichtigen Informationen rund um den BEANS Kosmos zu haben.
Warum SQLite?
Die Wahl des jeweiligen Datenbanksystems hat exakt den Grund, dass einige hier gerne Apps für Smartphones schreiben…und wie es der Zufall so will, kommt Android ziemlich gut mit SQLite klar, im Gegensatz zu anderen Systemen ^^
Zudem lässt sich SQL leicht in Rich-Client Anwendungen implementieren. Ich kann zwar nur für Java Anwendungen sprechen, denke aber, dass es auch in anderen Sprachen kein Problem sein dürfte, da SQL seit Ewigkeiten standardisiert ist.
Was für Informationen sollen in der Datenbank enthalten sein?
Hauptziel der Datenbank soll es (sehr viel) später einmal sein, sämtliche von den Bohnen gelieferte Inhalte kategorisieren zu können. Für mich bedeutet das, dass bestehende Youtube-System quasi um Informationen zu erweitern, die früher einmal im Blog auf gameone.de gestanden hätten. Aber was genau meine ich damit? Für mich fehlen im Youtube-System grundlegende Informationen: Zwar steht im Titel, wer in einem Video vorkommt, aber will man spezifisch nach Mitarbeitern suchen, haut Youtube nur Mist raus. Beispiel: Ich schaue gern LP mit Dennis R., weshalb ich ab und an einfach danach suche. Was haut Youtube bei dieser Suche raus? Drölfzig Teile von Civ 6. Wäre es nicht viel besser, wenn einem die Reihen angezeigt werden würden, die er mal gespielt hat? Anstatt hundert Teile der gleichen Reihe?
Und wäre es nicht nett, wenn einem zusätzlich dazu eine kurze Zusammenfassung angezeigt werden würde, was in der Folge so passiert? Wäre es nicht nützlich zu wissen, ob die Reihe noch läuft oder ob sie abgeschlossen/abgebrochen ist? Oder wenn ich gerade ein Video schaue, warum kann ich dann nicht einfach schnell den Namen des Mitarbeiters anklicken und mir werden ein Bild und eine kurze Beschreibung angezeigt? Oder auf welche Spitznamen er hört?
Was ist, wenn ich nach Themen suchen will? SciFI, Western und Konsorten? Kann ich das auf Youtube? Was ist, wenn ich nur Laberformate suchen will? Oder wenn ich nur Videos sehen will, in denen ein bestimmter Mitarbeiter eben nicht vorkommt, weil er mir, warum auch immer, unsympathisch ist/ich seiner gerade überdrüssig bin?
Kurzum nochmal zusammengefasst: Die geplante Datenbank soll für Programmierer rund um den BEANS Kosmos zusätzliche Informationen bereitstellen. Wenn sie einmal fertig ist, soll sie bspw. alle Videos der Beans mit zusätzlichen Informationen versehen. Da die Beans weiterhin munter Inhalte produzieren, ist das ein Kampf gegen Windmühlen, weshalb ich mir noch was überlegen muss, um zumindest das Eintragen der jeweiligen Videos und ein paar der Informationen zu automatisieren. Das ist allerdings noch Zukunftsmusik.
Ein Beispiel:
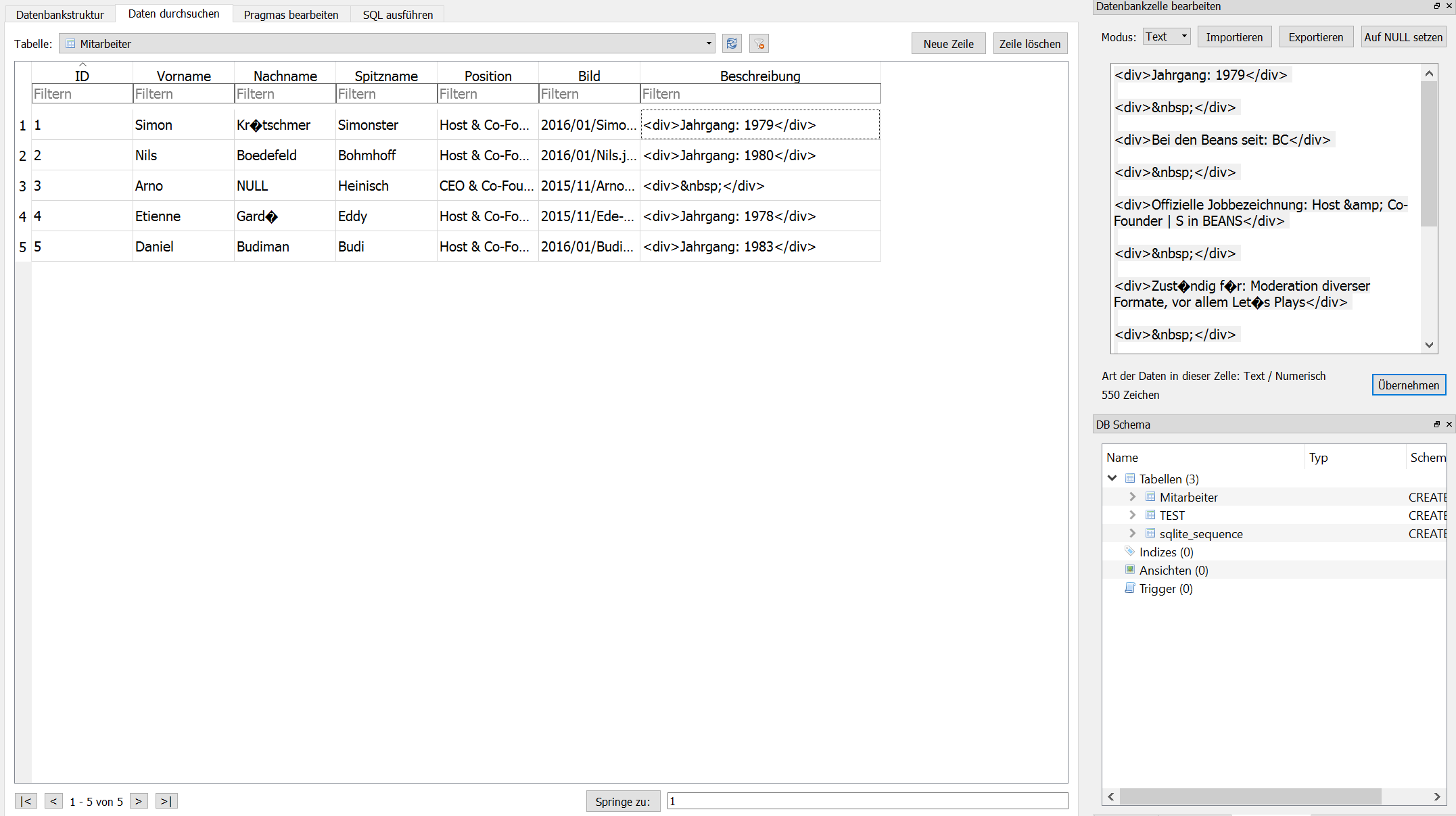
Hier ein Entwurf für eine Relation die alle Mitarbeiter der Beans enthält. Der Entwurf ist nicht final und da es gerade spät ist, enthält er sicherlich auch noch Fehler, aber er zeigt zumindest einen ersten Ansatz.
Bspw. würde ich das Attribut „Spitzname“ in eine eigene Relation auslagern, da jeder Mitarbeiter mehrere Spitznamen haben kann.
Da sie nur einen ersten Eindruck schaffen soll, habe ich bisher nur 5 Einträge vorgenommen. Außerdem ist sie auch noch nicht 100% richtig eingestellt.
Die angegeben Bilder sind Teile der URLs hier auf der Bohnen Seite. Zusammen mit https://www.rocketbeans.tv/wp-content/uploads/
ergeben sie dort angegebenen Bilder der Mitarbeiter.
Die Beschreibung wurde als Rich text gespeichert und auch der Seiter hier entnommen.